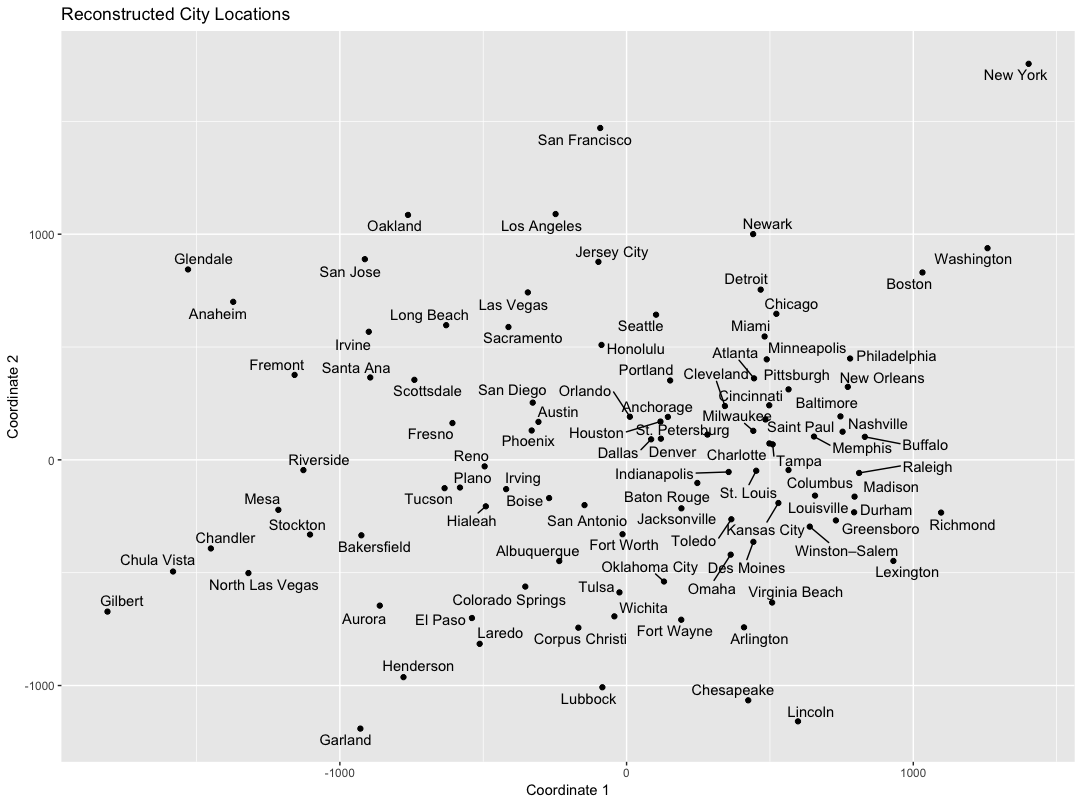
The way we use words in language encodes a lot of information about the real-world meaning of those words. Continue reading Reconstructing geographic distance among cities using distributional semantics
The way we use words in language encodes a lot of information about the real-world meaning of those words. Continue reading Reconstructing geographic distance among cities using distributional semantics
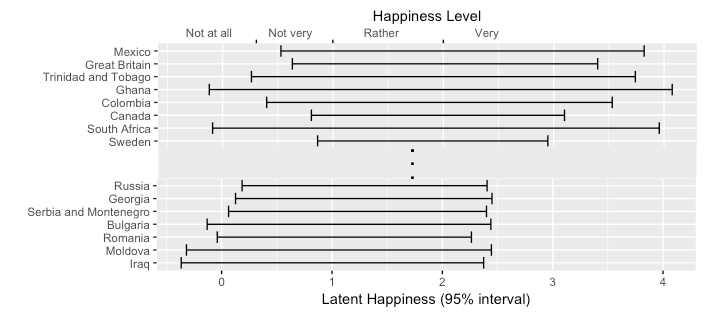
Often, when studying people’s subjective experiences, data are collected by asking survey participants to report on an ordinal scale how much they agree with a statement or question. Continue reading What country is the happiest? Interpreting ordinal-scale data