Text classification is a fundamental problem type in NLP and also serves as a common benchmark task in evaluating representations of text for machine learning. In this post, I’ll use the Large Movie Review Dataset from Maas et al. (2011). This dataset provides 25,000 movie reviews from IMDb for the benchmark task of classifying reviews as either positive (user rating 7-10) or negative (user rating 1-4). This task is known as sentiment analysis but the techniques are applicable to other text classification problems like spam filtering, topic classification and language detection.
A simple and useful way to represent text for classification is the bag of words. Each text is represented as a vector with length equal to the vocabulary size, where the value indicates the number of times that word occurs in the text.
An obvious drawback to this method is it completely ignores any information about word order. It’s therefore unable to capture more complex aspects of meaning encoded in the relationships between words and phrases, or to distinguish between different senses of a word.
In this post, we’ll mitigate this problem by including highly informative bigrams and trigrams in addition to individual words. Since the number of unique bigrams and trigrams is very large, and most of them are rare and indicate a sentiment polarity roughly consistent with that of their component words, we don’t want to include them all in the model and end up with tens of thousands of uninformative features. Instead we’ll select only the bigrams and trigrams with estimated polarity that is significantly different from what would be expected based on the individual words.
Data Preparation
I tokenized the texts into words, removing any HTML tags. I also separated the training data into a training (70%) and validation (30%) set. The resulting training set consists of 17,500 movie reviews, evenly split between positive and negative. 90% of the review lengths are between 75 and 698 words. Our movie review samples then look something like this (feature generation will ignore capitalization and drop punctuation tokens):
['This', 'is', 'not', 'the', 'typical', 'Mel', 'Brooks', 'film', '.', 'It', 'was', 'much', 'less', 'slapstick', ...]
Positive and Negative Sentiment Words
First, let’s check which words have the strongest sentiment polarity signals. Our numerical measure of polarity will be the log of the ratio of the word’s frequency in positive reviews versus negative reviews. Restricting to words with frequency at least 1 in 10,000, the most positive and negative words are:
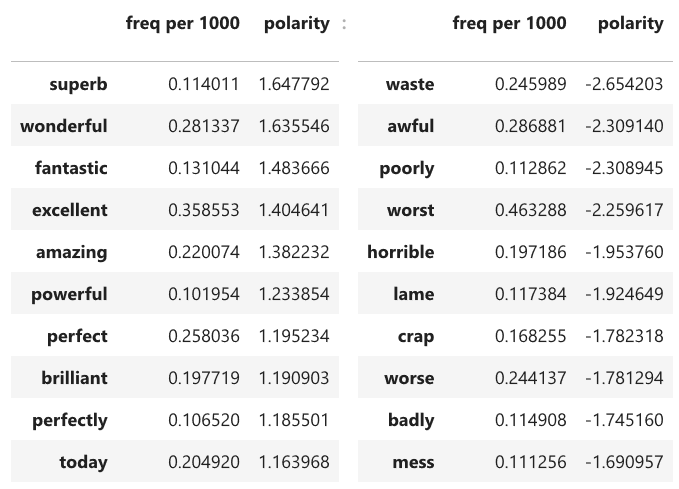
That makes sense, although I was surprised that today is so much more common in positive reviews.
Unexpectedly Positive and Negative n-Grams
There are 78,295 unique words, 125,004 unique bigrams, and 495,856 unique trigrams in the training set. Since most of these are uninformative, we want to select the most relevant bigrams and trigrams to augment the bag-of-words feature set.
I used a linear model to estimate the expected polarity of each n-gram based on its component words. I trained separate models for bigrams and trigrams. Using all n-grams that appeared at least once in every 50,000 tokens, I trained a linear model with coefficients for the polarities of the most polar word, least polar word, and intermediate polarity word (for the trigram model):
| Coefficients | Bigram Model | Trigram Model |
| Least polar | 0.625 | 0.188 |
| Intermediate | – | 0.733 |
| Most polar | 1.118 | 1.238 |
It is mostly the most polar word within an n-gram that defines the polarity of the n-gram overall, although all words matter to some extent.
We can then identify bigrams and trigrams that are more positive or more negative than expected and select only those to use as model features.
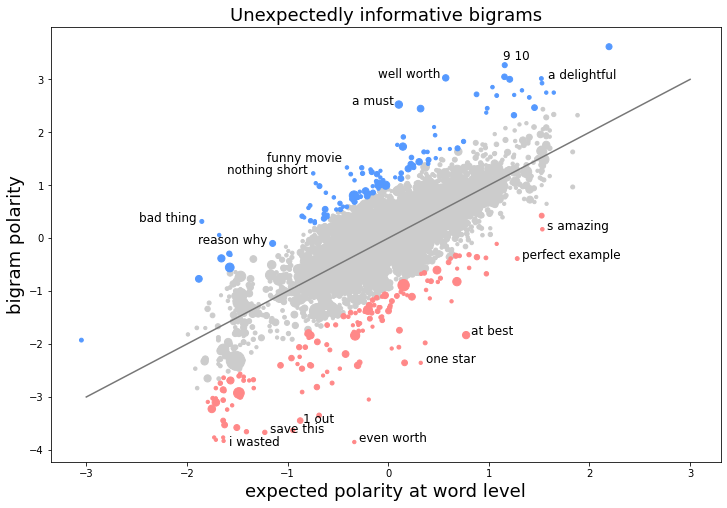
Positive bigrams made out of negative words include bad thing (as in, the one bad thing about this good movie) and “reason why”. Bigrams that are expected to be positive but turn out to be even more so include 9/10 and a delightful. Negative bigrams made out of positive words include at best and one star. Bigrams that are expected to be negative but turn out to be even more so include I wasted and save this.
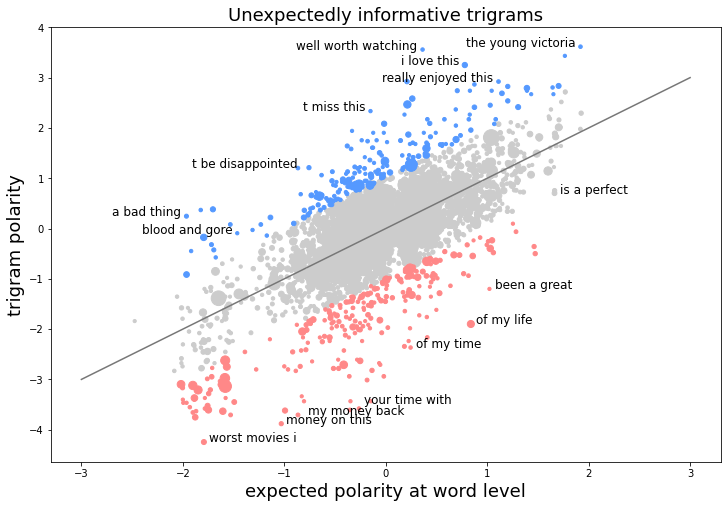
The same analysis with trigrams turns up some characteristically multi-word sentiment indicators like (you won’)t be disappointed and (would have) been a great, but also some that appear to be movie-specific (blood and gore, the young victoria) that we might not expect to generalize.
Feature Selection
The next step is to select a subset of the ~700,000 features to include in the model. I decided to select bigrams and trigrams using a minimum cutoff for frequency and polarity, and then fill with the top words (ranked by frequency with a small adjustment for polarity to boost high-polarity words near the frequency cutoff) up to the desired total number of features. The cutoff levels are hyperparameters that I set by choosing values that give good predictions on the validation set. I also consider models that drop stopwords (common, nonspecific words like the, for, and).
Logistic Regression Model
scikitlearn’s implementation of logistic regression is a basic but effective technique for binary classification. Below are my top results on the validation set with different settings for feature generation:
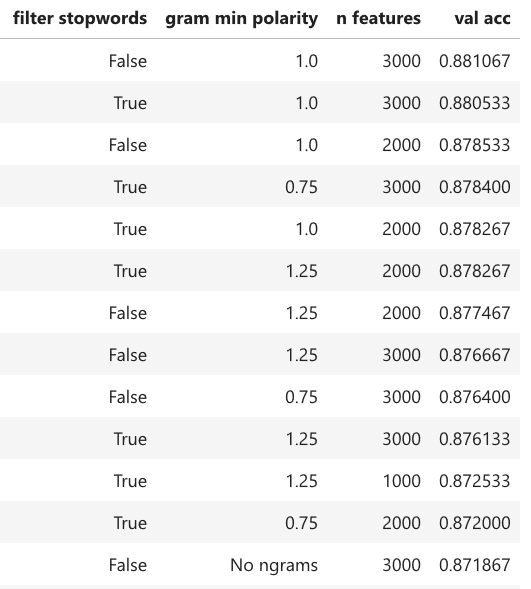
The best results are obtained with no stopword filtering, minimum n-gram polarity of 1 (log ratio units) and 3000 total features. Adding n-grams to the model improves the accuracy by almost 1 percentage point compared to the pure bag-of-words model.
Training with Keras
To evaluate how the augmented bag of words features perform with different model types, I also trained a neural net model using Keras. I used a feed-forward fully connected network with two hidden layers, ReLu activation function and binary cross-entropy loss. I set the training to stop early when the validation accuracy no longer increased with additional epochs. This training takes a couple of minutes on my laptop’s CPU.
Results
Although the neural net model performed better on validation, it was slightly worse on test (maybe using the validation results to choose the stopping epoch slightly biased the validation accuracy upward). Overall, we achieve 88% accuracy which is comparable to benchmark results using methods based on bag of words representations. For comparison, 93% accuracy has been reported on this dataset using BERT, a state-of-the-art sequence-based text representation trained on very large text corpora.
| Logistic Regression | 0.8799 |
| Feed-forward NN | 0.8785 |
| Keras Tutorial (Vector embedding + Convolutional NN) | 0.8650 |
| Maas et al. (2011) Baseline (Bag of Words SVM) | 0.8780 |
| Maas et al. (2011) Full (Bag of Words + Semantic/Sentiment Vector SVM) | 0.8889 |
| BERT (Sanh et al., 2019) | 0.9346 |
Discussion
One might think it would be easier to get over 90% accuracy on this task as the texts are relatively clean and relevant and the training set is large. What kinds of language are confusing the model? Looking at some misclassified texts we can see some patterns. Often, positive-sentiment or negative-sentiment language occurs but refers to something other than the movie. For instance, one review praised a film for its willingness to portray negative aspects of its historical protagonist. One negative review even contained the phrase “extremely well written” in reference to another user’s critical comments about the film. Without the ability to bind comments to topics, we can only identify reviews with a preponderance of positive or negative comments, but not the specific entity that is being praised or criticized.
Another tendency of the reviews is to flip back and forth between positive and negative comments, ending with something like “Overall, it is fun to watch.” Expressions like Overall or All in all or In the end cue the reader to interpret the following comment as a global assessment of the film whereas opposite-polarity comments are specific to particular aspects that don’t make or break it, but our model can’t learn to condition the importance of one phrase on its position in the discourse relative to another.
Other times, reviewers expressed the idea of the movie being good or bad, but not actually making that assertion, e.g. people said this was a great movie. Our model isn’t able to detect the contextual cues that distinguish direct statements from various types of indirect speech, quotations, sarcasm, rhetorical questions, and the like.
Overall, our n-gram selection technique efficiently upgrades the bag-of-words model to a bag-of-words-and-phrases model without significantly increasing the size of the model, as would be necessary for a full bigram or trigram model. We achieve decent results with either logistic regression or feed-forward NN by detecting positive or negative linguistic elements. However, the performance of our model is limited by its lack of any level of language understanding that could reliably distinguish between positive/negative sentiment statements that make assertions about the main topic and those that do not.
Code
View the Python code used for this post at: https://github.com/lucasmchang/text_classification/blob/main/movie_reviews_sentiment.ipynb